Robust Video Registration Applied to Field-Sports Video Analysis
- Posted on May 10, 2013 at 3:23 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
Published in ICASSP 2012.

Video (image-to-image) registration is a fundamental problem in computer vision. Registering video frames to the same coordinate system is necessary before meaningful inference can be made from a dynamic scene in the presence of camera motion. Standard registration techniques detect specific structures (e.g. points and lines), find potential correspondences, and use a random sampling method to choose inlier correspondences. Unlike these standards, we propose a parameter-free, robust registration method that avoids explicit structure matching by matching entire images or image patches. We frame the registration problem in a sparse representation setting, where outlier pixels are assumed to be sparse in an image. Here, robust video registration (RVR) becomes equivalent to solving a sequence of L1 minimization problems, each of which can be solved using the Inexact Augmented Lagrangian Method (IALM). Our RVR method is made efficient (sublinear complexity in the number of pixels) by exploiting a hybrid coarse-to-fine and random sampling strategy along with the temporal smoothness of camera motion. We showcase RVR in the domain of sports videos, specifically American football. Our experiments on real-world data show that RVR outperforms standard methods and is useful in several applications (e.g. automatic panoramic stitching and non-static background subtraction).
Authors:
Bernard Ghanem
Zhang Tianzhu
Narendra Ahuja
Documents:
Paper (pdf)
Poster (ppt)
Acknowledgement:
This study is supported by the research grant for the Human Sixth Sense Programme at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).
Robust Visual Tracking via Multi-Task Sparse Learning
- Posted on at 3:18 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
Published in CVPR 2012.
![]()
In this paper, we formulate object tracking in a particle filter framework as a multi-task sparse learning problem, which we denote as Multi-Task Tracking (MTT). Since we model particles as linear combinations of dictionary templates that are updated dynamically, learning the representation of each particle is considered a single task in MTT. By employing popular sparsity-inducing `p;q mixed norms (p 2 f2;1g and q = 1), we regularize the representation problem to enforce joint sparsity and learn the particle representations together. As compared to previous methods that handle particles independently, our results demonstrate that mining the interdependencies between particles improves tracking performance and overall computational complexity. Interestingly, we show that the popular L1 tracker [15] is a special case of our MTT formulation (denoted as the L11 tracker) when p = q = 1. The learning problem can be efficiently solved using an Accelerated Proximal Gradient (APG) method that yields a sequence of closed form updates. As such, MTT is computationally attractive. We test our proposed approach on challenging sequences involving heavy occlusion, drastic illumination changes, and large pose variations. Experimental results show that MTT methods consistently outperform state-of-the-art trackers.
People:
Zhang Tianzhu
Bernard Ghanem
Narendra Ahuja
Documents:
paper (preprint pdf)
Bib
Source code:
code
Acknowledgement:
This study is supported by the research grant for the Human Sixth Sense Programme at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).
Context-Aware Learning for Automatic Sports Highlight Recognition
- Posted on at 3:16 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
Published in ICPR 2012.
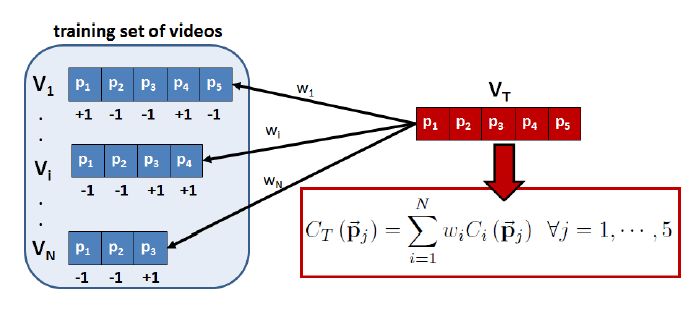
Video highlight recognition is the procedure in which a long video sequence is summarized into a shorter video clip that depicts the most “salient” parts of the sequence. It is an important technique for content delivery systems and search systems which create multimedia content tailored to their users’ needs. This paper deals specifically with capturing highlights inherent to sports videos, especially for American football. Our proposed system exploits the multimodal nature of sports videos (i.e. visual, audio, and text cues) to detect the most important segments among them. The optimal combination of these cues is learned in a data-driven fashion using user preferences (expert input) as ground truth. Unlike most highlight recognition systems in the literature that define a highlight to be salient only in its own right (globally salient), we also consider the context of each video segment w.r.t. the video sequence it belongs to (locally salient). To validate our method, we compile a large dataset of broadcast American football videos, acquire their ground truth highlights, and evaluate the performance of our learning approach.
People:
Bernard Ghanem
Maya Kreidieh
Marc Farra
Tianzhu Zhang
Documents:
paper (preprint pdf)
Bib
Acknowledgement:
This study is supported by the research grant for the Human Sixth Sense Program at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).
Trajectory-based Fisher Kernel Representation for Action Recognition in Videos
- Posted on at 3:13 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
Published in ICPR 2012.

Action recognition is an important computer vision problem that has many applications including video indexing and retrieval, event detection, and video summarization. In this paper, we propose to apply the Fisher kernel paradigm to action recognition. The Fisher kernel framework combines the strengths of generative and discriminative models. In this approach, given the trajectories extracted from a video and a generative Gaussian Mixture Model (GMM), we use the Fisher Kernel method to describe how much the GMM parameters are modified to best fit the video trajectories. We experiment in using the Fisher Kernel vector to create the video representation and to train an SVM classifier. We further extend our framework to select the most discriminative trajectories using a novel MIL-KNN framework. We compare the performance of our approach to the current state-of-the-art bag-of-features (BOF) approach on two benchmark datasets. Experimental results show that our proposed approach outperforms the state-of the- art method [8] and that the selected discriminative trajectories are descriptive of the action class.
People:
Indriyati Atmosukarto
Bernard Ghanem
Narendra Ahuja
Documents:
paper (preprint pdf)
Bib
Acknowledgement:
This study is supported by the research grant for the Human Sixth Sense Programme at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).
Low Rank Sparse Learning for Robust Visual Tracking
- Posted on at 3:09 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
Published in ECCV 2012.
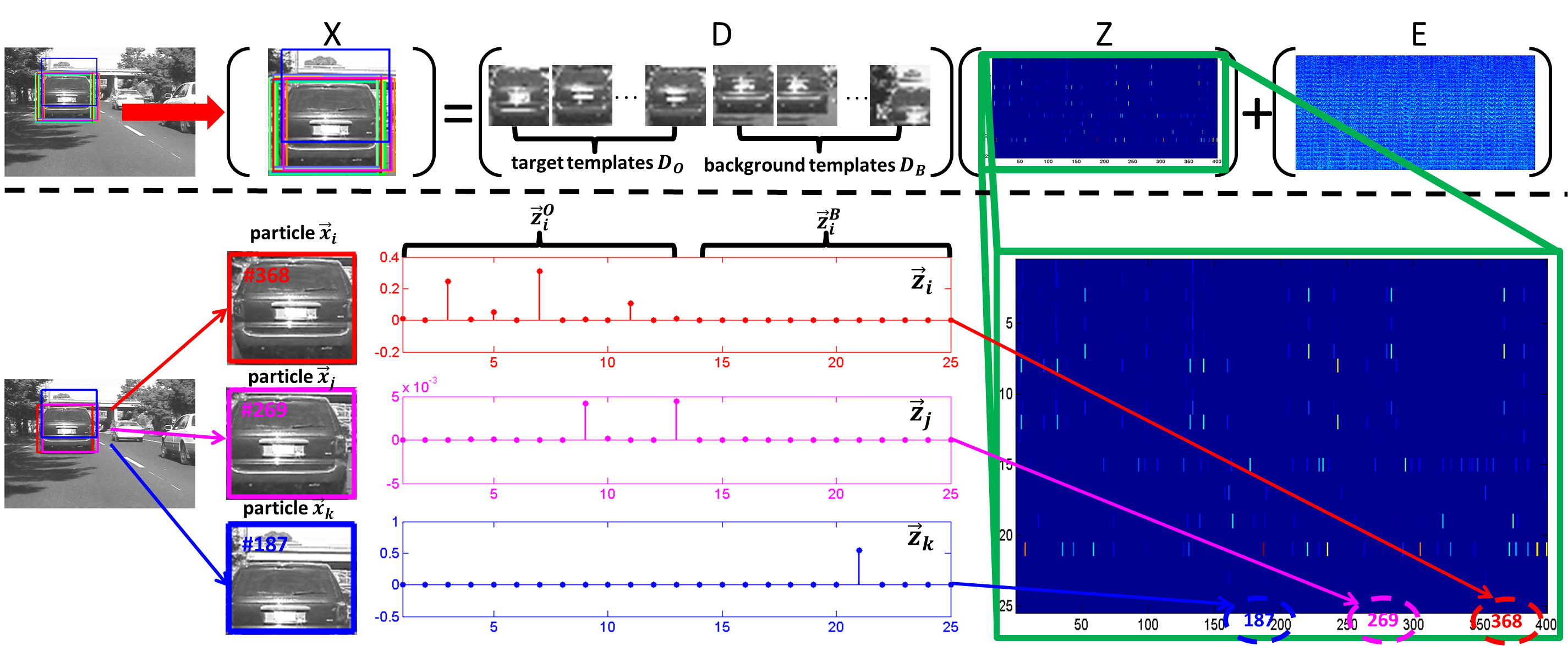
This study is supported by the research grant for the Human Sixth Sense Programme at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).
Robust Visual Tracking via Structured Multi-Task Sparse Learning
- Posted on at 3:01 pm by kcarr1@illinois.edu.
- Categorized Uncategorized.
People:
Tianzhu Zhang
Bernard Ghanem
Si Liu
Narendra Ahuja
Documents:
paper (pdf)
Acknowledgement:
This study is supported by the research grant for the Human Sixth Sense Programme at the Advanced Digital Sciences Center from Singapore’s Agency for Science, Technology and Research (A*STAR).